What “Appearing in ChatGPT” Actually Means
When someone says their brand “appears in ChatGPT,” they could mean several fundamentally different things, and conflating them leads to bad strategy.
Training-Based Recall
ChatGPT’s base models (GPT-4, GPT-4o, GPT-4.1) were trained on massive text corpora with a knowledge cutoff. If your brand was mentioned frequently enough across high-quality sources before that cutoff date, the model has internalized associations between your brand name and specific topics, products, or categories. When a user asks “What are the best project management tools?”, the model doesn’t search a database — it generates an answer based on statistical patterns. Brands like Asana, Monday.com, and Notion appear because they were mentioned thousands of times across training data in exactly that context. This is recall, not ranking.
Retrieval-Augmented Answers
ChatGPT with browsing enabled (and now ChatGPT Search) can pull real-time information from the web, primarily through Bing’s index. When this happens, the model is combining its trained knowledge with fresh search results. Your brand could appear here even if it wasn’t prominent in training data — provided your content is indexed, crawlable, and relevant to the query. But retrieval doesn’t activate for every query. Simple factual questions, opinion-based prompts, and conversational queries often get answered entirely from the model’s training, with no web lookup at all.
The Three Query Types
AI responses vary dramatically depending on query type, and each has different visibility dynamics:
Known-entity queries (“What is Salesforce?” or “Tell me about HubSpot”) — The model either recognizes your brand or it doesn’t. If you’re an established entity with thousands of web mentions, you’ll get a reasonable description. If you’re a startup with 50 pages of web presence, the model may hallucinate details or say it doesn’t have information.
Comparative queries (“Best CRM tools for small business” or “Alternatives to Mailchimp”) — This is where most brands want to appear and where the competition is fiercest. The model draws from training data patterns, and the brands that appear most frequently in “best of” lists, comparison articles, and review sites during training dominate these answers. For newer models with search, it’s a blend of trained associations and live search results.
Exploratory queries (“How to set up email automation” or “How to improve website conversion rates”) — These informational queries sometimes include brand mentions as examples or tool recommendations. Appearing here requires your brand to be tightly associated with the topic across multiple sources — not just on your own website.
No Fixed Ranking System
This is the hardest concept for people coming from SEO: there are no positions. Google has ten blue links. You’re either #1 or #7 or not on page one. ChatGPT has none of that. Ask the same question twice, and you might get different brands mentioned, in different order, with different framing. The output is probabilistic. Token prediction means the model is constantly making choices about which word comes next, and small variations in phrasing, conversation history, or even random sampling temperature can shift which brands surface. You cannot “rank #1 in ChatGPT.” You can increase the probability that your brand appears — but that probability is never 100%.
The Myths That Are Wasting Your Budget
A cottage industry has sprung up around “ChatGPT SEO” and “AI search optimization,” and a significant portion of what’s being sold is either misleading or flatly wrong. Here’s what doesn’t work the way vendors claim.
“ChatGPT SEO” Is Not a Discipline
There is no ranking algorithm to reverse-engineer. There is no submission process. There are no meta tags that signal to ChatGPT that your page should be included. Companies selling “ChatGPT SEO packages” are typically repackaging traditional SEO with new terminology. Some of those traditional SEO activities happen to help with AI visibility (structured content, authority building, entity optimization), but calling it “ChatGPT SEO” implies a level of control and predictability that doesn’t exist.
AEO/GEO: Partially Right, Mostly Incomplete
Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO) are real concepts with genuine substance behind them. AEO focuses on making content extractable — structuring answers so that AI systems can pull clean responses. GEO focuses on the generative layer — understanding how LLMs construct answers and positioning content to be included. Both have merit. But they’re both incomplete because they focus overwhelmingly on content, and content alone is insufficient. We’ve seen brands with perfectly structured, semantically rich content that never appear in AI answers because they lack the external authority signals that drive model confidence. A well-structured FAQ page on a domain with no backlinks, no press coverage, and no third-party mentions is invisible to both trained models and retrieval systems.
The “Optimize and They Will Come” Fallacy
The most dangerous misconception: if you structure your content correctly and target the right queries, AI systems will find and use your content. This confuses necessary conditions with sufficient conditions. Good content structure is necessary. But it’s only one input among many. The model’s decision to mention your brand depends on:
- Whether your brand exists in training data at all
- How frequently it appears relative to competitors
- What context surrounds those mentions (positive, negative, neutral)
- Whether third-party sources validate your brand’s authority
- Whether retrieval-enabled queries find your content through Bing
Optimizing your own website is like renovating your house and expecting foot traffic to increase. The house might be beautiful, but if nobody knows it exists, nobody walks through the door.

How the System Actually Works: Training, Retrieval, and Generation
To build effective strategy, you need to understand the three layers that determine whether your brand surfaces in an AI response.
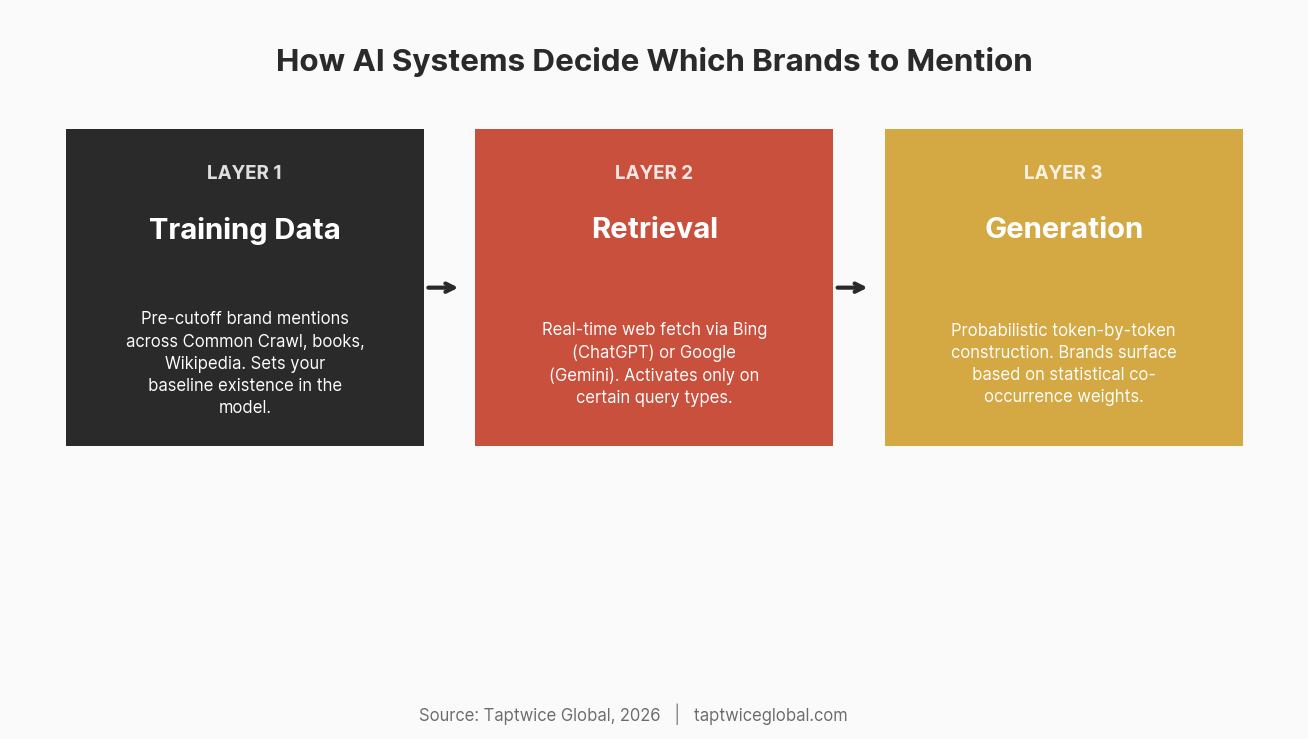
Layer 1: Training Data
Large language models are trained on web crawl data (Common Crawl), books, academic papers, code repositories, Wikipedia, news archives, and various other public datasets. The exact composition of training data is proprietary, but we know the general shape from research papers and documentation published by OpenAI, Google, and others.
Your brand’s presence in this training data determines its “baseline existence” in the model. If your brand was mentioned 10,000 times across diverse, authoritative sources before the training cutoff, the model has a strong internal representation. If your brand was mentioned 50 times, mostly on your own website and a few directory listings, the model’s representation is weak or nonexistent.
This creates what we call the existence problem: for brands that weren’t prominent before the training cutoff, no amount of on-site optimization will make them appear in the model’s trained knowledge. You’re optimizing for a system that has never heard of you. This problem partially resolves with retrieval-augmented generation (discussed below), but only for queries where the model actually searches the web.
Layer 2: Retrieval
ChatGPT Search (and similar features in Gemini, Perplexity, and Claude) can fetch real-time information from the web. This is where newer and smaller brands have their best opportunity. When retrieval activates, the model queries a search index (Bing for ChatGPT, Google for Gemini), pulls relevant pages, and incorporates that information into its response.
But retrieval has significant limitations:
It doesn’t activate for every query. Conversational queries, opinion requests, and general knowledge questions often bypass retrieval entirely. The model answers from training data alone.
It depends on existing search index rankings. If your page doesn’t rank in Bing for relevant queries, ChatGPT Search won’t find it. This is where traditional SEO directly impacts AI visibility — not because ChatGPT cares about your meta tags, but because its retrieval system piggybacks on search engine infrastructure.
Retrieval results get filtered through the model’s judgment. Even when the model finds your page, it decides whether to cite it based on perceived authority, relevance, and content quality. A page from a no-name domain competing against established players may be retrieved but not mentioned.
Layer 3: Generation
The final layer is where the model actually constructs its response. Given everything it knows (training data) and everything it just found (retrieval results), it generates text token by token. Each token is chosen based on probability — what word is most likely to come next given all the context.
This is where brand strength matters most. When the model generates a list of “best email marketing platforms,” it’s drawing on statistical patterns. If “Mailchimp” appeared next to “email marketing” tens of thousands of times in training data, it has high probability of being generated. Your brand, which appeared next to “email marketing” a few hundred times, has low probability. The model isn’t making quality judgments — it’s making probabilistic predictions that happen to correlate with popularity and authority.
Entity Signals: The Concept Most People Miss
If there’s one framework that explains AI brand visibility better than any other, it’s entity signals. This borrows from knowledge graph theory and applies directly to how LLMs process brand information.
Your Brand as a Node
Think of the model’s internal knowledge as a massive, implicit graph. Each entity — brand, person, concept, product — is a node. The connections between nodes represent relationships: “Shopify” connects to “e-commerce,” “small business,” “website builder,” “Tobi Lütke,” “Stripe integration,” and hundreds of other concepts. The strength of each connection depends on how frequently and consistently those associations appeared in training data.
Your brand’s node might be tiny — few connections, weak associations, no clear category. Or it might not exist at all. Building AI visibility is fundamentally about building this node: creating strong, consistent, and diverse connections between your brand and the topics where you want to appear.
What Strengthens Entity Signals
Frequency of mentions: Raw volume matters, but with diminishing returns. The jump from 0 mentions to 100 across authoritative sources is enormous. The jump from 1,000 to 1,100 is negligible.
Context consistency: If your brand is mentioned in the context of “AI search optimization” across dozens of different sources — news articles, blog posts, forums, interviews — the model builds a strong association. If mentions are scattered across unrelated topics, the signal is diluted.
Source diversity: Mentions on your own website count for very little. Mentions across different domains, different content types, and different authors create a stronger, more durable signal. The model essentially triangulates — if multiple independent sources associate your brand with a topic, that association becomes statistically reliable.
Entity Co-occurrence
This is where it gets tactical. Entity co-occurrence refers to how often your brand appears near specific keywords and concepts across the web. If “Taptwice Global” consistently appears within close proximity to “AI search optimization,” “GEO,” “entity SEO,” and “brand visibility in AI” across news articles, guest posts, and industry discussions, the model’s internal representation of our brand strengthens its association with those specific topics.
Co-occurrence also works with other entities. When your brand is mentioned alongside recognized leaders in your space — in comparisons, case studies, or industry roundups — you inherit some of their entity strength through association. This isn’t manipulation; it’s how statistical language models naturally build representations.
Why Authority Signals Outweigh Content Optimization
Here’s a position most “AI SEO” content won’t take: for the majority of brands, third-party authority signals matter more than on-site content optimization for AI visibility. Content optimization is table stakes. Authority is the differentiator.
Third-Party Validation
When The Verge, TechCrunch, or Forbes mentions your brand in an article, that mention carries disproportionate weight. These domains appear heavily in training data. Their content is frequently crawled, cached, and cited. A single mention of your brand in a New York Times article about your industry might do more for your AI visibility than six months of blog content on your own site.
This isn’t speculation. In our citation analysis work across nearly 4,000 URLs from AI discovery data, we consistently see the same pattern: brands that appear in AI answers have extensive third-party coverage. Brands with comparable or even superior on-site content but minimal external coverage rarely surface.
Platform Bias in Training Data
Reddit is dramatically overrepresented in AI training data and retrieval results. Perplexity cites Reddit threads constantly. ChatGPT references Reddit discussions when answering product comparison queries. Google’s AI Overviews pull from Reddit at rates that far exceed its traditional search ranking position.
This means organic Reddit presence — genuine discussions where your brand is recommended by actual users — has outsized impact on AI visibility. The same applies to Stack Overflow for developer tools, Quora for general knowledge, and specialized forums for niche industries. User-generated content on these platforms carries a weight that surprises most marketers accustomed to focusing on their owned media.
The Citation Hierarchy
Not all mentions are equal. Through our analysis, we’ve observed a rough hierarchy of mention impact:
- Major news outlets and industry publications — highest signal strength per mention
- Wikipedia and WikiData — extremely high for entity recognition (if you have a Wikipedia page, models almost certainly know you exist)
- Reddit, Stack Overflow, and active forums — high volume presence in training data, strong retrieval signals
- Established blogs and content platforms (Medium, Substack, LinkedIn) — moderate signal, valuable for co-occurrence building
- Industry directories and review sites (G2, Capterra, Clutch) — moderate for category association
- Your own website — lowest authority signal, but critical for content structure and retrieval
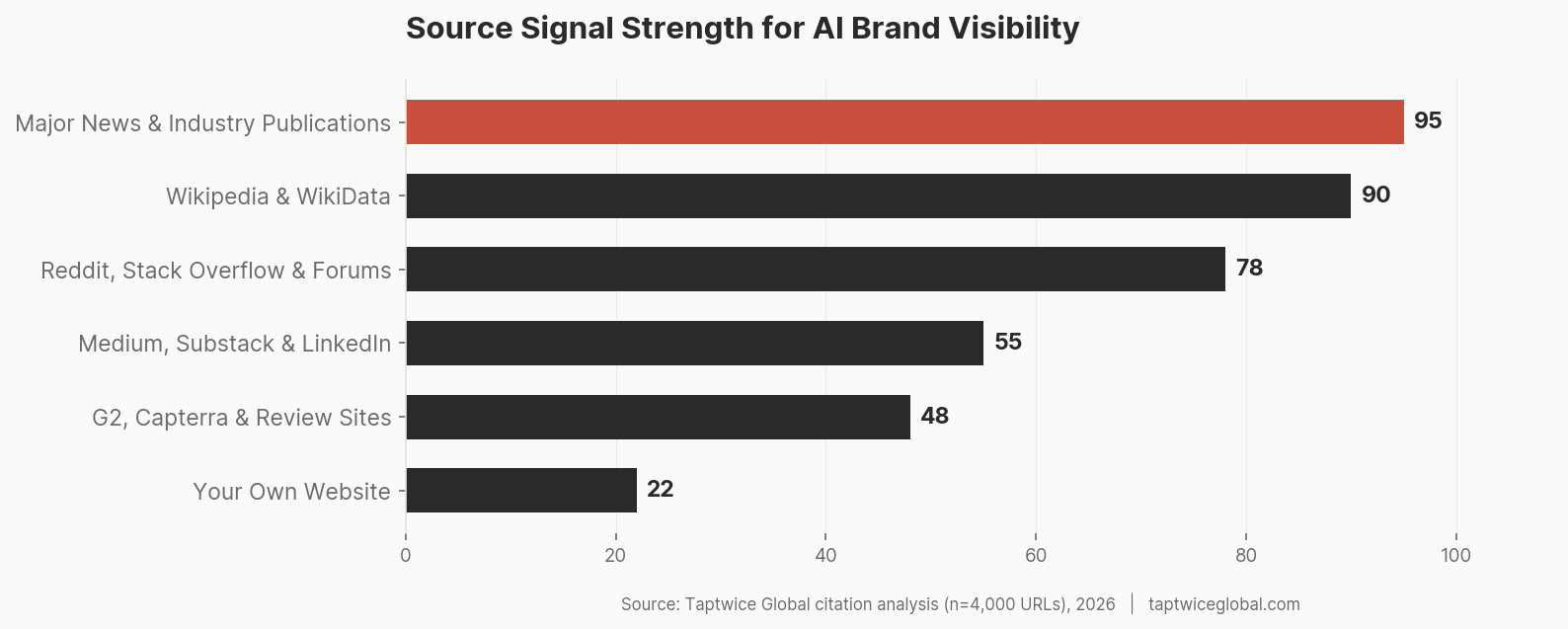
The paradox: most brands invest 90% of their effort on #6 and wonder why they’re invisible.
Query Behavior: Why You Appear for Some Queries and Not Others
One of the most frustrating aspects of AI visibility is inconsistency. You might appear for one query and vanish for a nearly identical query phrased slightly differently. This isn’t random — it follows patterns rooted in how models process different query types.
Known vs. Discovery Queries
If someone asks “What is [Your Brand]?” — a known-entity query — your inclusion rate depends almost entirely on whether the model has a stored representation of your brand. Established brands see near-100% inclusion for their own name queries. Unknown brands see near-0%.
Discovery queries (“best tools for X,” “alternatives to Y,” “how to solve Z”) are the battleground. Inclusion rates here are dramatically lower for any individual brand. Even market leaders might only appear in 40-60% of variations of a relevant discovery query. Smaller brands might appear in single-digit percentages. This is normal. The goal isn’t 100% appearance — it’s increasing your probability relative to competitors.

Phrasing Sensitivity
Ask ChatGPT “What are the best CRM tools?” and you’ll get one list. Ask “What CRM should a 10-person startup use?” and you’ll get a different list. Ask “Which CRM has the best email automation?” and you’ll get yet another. Each phrasing activates different associations in the model. The first query triggers broad popularity signals. The second activates “startup” and “small team” associations. The third activates feature-specific knowledge.
This means your brand can be invisible for broad category queries but highly visible for specific niche queries — if your entity signals are strong for that niche. A small CRM that’s frequently discussed in startup communities might outperform Salesforce for “best CRM for bootstrapped startups” while being completely absent from “best CRM tools” generally.
Intent Mapping
AI models, like search engines, interpret query intent. But they do it differently. A search engine shows blue links and lets the user decide. An AI model decides for the user, selecting which brands deserve mention based on its interpretation of intent.
For informational intent (“how does CRM work”), brand mentions are incidental — the model may use your brand as an example. For commercial intent (“best CRM for sales teams”), brand mentions are central — the model is essentially making recommendations. For navigational intent (“HubSpot pricing”), the model focuses on a single brand. Understanding which intent bucket your target queries fall into determines what kind of content and external signals you need.
Content That Actually Moves the Needle
Content optimization does matter — it’s just not sufficient on its own. Here’s what makes content more likely to be extracted and used by AI systems.
Extractable Structures
AI models (especially during retrieval) favor content that provides clean, direct answers. This isn’t about structured data markup (though that helps at the margins). It’s about how you write:
Direct definitions: “[Term] is [clear definition].” When your content provides an unambiguous, concise definition, models can extract it cleanly. Compare “Email marketing is the practice of sending targeted commercial messages to a subscribed audience via email” with three paragraphs of preamble before getting to what email marketing is.
Comparison structures: Side-by-side comparisons with clear differentiators give models extractable content for “X vs Y” queries. The model can pull your comparison framework directly into its response.
Lists with context: Not just “Top 10 Tools” but “Top 10 Tools” where each entry includes what the tool does, who it’s for, and what makes it different. Thin listicles get passed over; substantive lists get cited.
Semantic Clarity Over Keyword Density
Keyword stuffing was already dying in traditional SEO. In AI contexts, it’s actively harmful. Models respond to semantic clarity — the degree to which your content consistently and clearly addresses a single topic cluster.
A page about “email marketing automation” that drifts into “social media scheduling” and “content management” dilutes its semantic signal. A page that deeply covers email marketing automation — workflows, triggers, A/B testing within automated sequences, integration with CRM systems — builds a strong topical signal that models can confidently associate with related queries.
Structured Data as Reinforcement
Schema markup (FAQ schema, Organization schema, Product schema, Article schema) provides an additional signal layer. It doesn’t directly influence LLM training — models don’t read JSON-LD as structured data. But it improves how search engines index and display your content, which indirectly improves retrieval outcomes. It also helps AI systems that specifically parse structured data during their retrieval process. Think of it as reinforcement, not a primary driver.
Technical Foundations That Block or Enable Visibility
Before any content or authority strategy matters, your technical foundation needs to be solid. Several brands we’ve analyzed were completely invisible to AI systems for purely technical reasons.
Bot Access
OpenAI’s web crawler is OAI-SearchBot (and historically GPTBot). Perplexity uses PerplexityBot. Google’s AI systems use Googlebot. If your robots.txt blocks these crawlers, your content cannot be retrieved — period. We’ve seen enterprise sites with sophisticated content strategies that blocked AI crawlers in robots.txt because their security team treated them as scrapers. The result: zero AI visibility from retrieval-based answers.
Check your robots.txt now. If you see User-agent: GPTBot followed by Disallow: /, you’ve found your problem. The same applies to OAI-SearchBot, PerplexityBot, and any other AI crawler you want access from.
Search Engine Index Presence
Because retrieval-augmented generation depends on search indexes (primarily Bing for ChatGPT), your content must be indexed in those search engines. Most SEO professionals focus exclusively on Google indexing. But if your pages aren’t in Bing’s index, ChatGPT Search literally cannot find them. Submit your sitemap to Bing Webmaster Tools. Verify your pages are indexed. This takes ten minutes and can unlock an entire visibility channel.
Site Reliability
Crawlers, whether from search engines or AI companies, need to access your pages quickly and consistently. Slow-loading pages, intermittent downtime, aggressive rate limiting, and broken SSL certificates all reduce crawl success rates. If a crawler hits your site and gets a 503 error three times, it deprioritizes your domain. This is the same principle as traditional SEO technical health, applied to a broader set of crawlers.
The Biases Nobody Talks About
AI visibility is not a level playing field. Several structural biases work against certain types of brands and in favor of others. Acknowledging these biases is essential for setting realistic expectations and allocating resources effectively.
Established Brand Bias
Training data reflects the web as it was, not as it is. Brands that dominated web discourse before the training cutoff have an enormous structural advantage. If you launched your company in 2024, you missed GPT-4’s training window entirely. Your brand doesn’t exist in the model’s base knowledge. You’re competing against brands with years of accumulated web presence baked into the model’s parameters. This isn’t unfair — it’s physics. The model can only know what it was trained on.
Source Bias
Training data overweights certain sources. English-language content dominates. Western media outlets are overrepresented. Technical topics skew toward Stack Overflow and GitHub. Business topics skew toward a handful of major publications. If your brand primarily operates in non-English markets or in industries that don’t generate much online discussion, your AI visibility ceiling is structurally lower regardless of your brand quality.
Non-Determinism
The same prompt, entered at different times, with different conversation contexts, or even with different random seeds, can produce different brand mentions. This is a fundamental property of probabilistic text generation, not a bug. It means AI visibility cannot be measured with a single query. You need to test across dozens of query variations, at different times, and track patterns rather than individual results. Anyone claiming they can guarantee a specific brand will “always” appear in ChatGPT doesn’t understand how the system works.
Temporal Lag
Even with retrieval-augmented generation, there’s a recognition lag for new brands. Training data is static until the next training run. Retrieval depends on search index inclusion, which itself has a crawl-and-index delay. And even when fresh content is retrieved, the model’s base knowledge doesn’t change — it might mention your brand from a retrieved source but not from its own knowledge for months or years. Building AI visibility is a long game. Brands expecting instant results will be disappointed.
Competitive Dynamics: Why Your Competitor Appears and You Don’t
This is the question that drives most brands to investigate AI visibility in the first place. The answer is usually simpler than people expect — and harder to fix than they hope.
The Winner-Takes-Most Effect
When ChatGPT generates a list of “best tools” in any category, it typically mentions 3-7 brands. In most categories, hundreds of brands compete. This means AI answers have an extreme concentration effect — far more concentrated than Google’s first page, which shows 10 results. The top few brands in any category capture a disproportionate share of AI mentions, and the gap between #3 and #10 in AI visibility is much larger than the same gap in search rankings.
If your competitor consistently appears in the top 3-5 brands mentioned for your category queries, they’ve likely crossed a threshold of entity strength that puts them in the model’s “default” consideration set. Getting into that set requires significant, sustained investment in external authority signals.
Category Saturation
Some categories are so saturated with established brands that breaking in is extremely difficult. “Best CRM” is a nearly impenetrable query — Salesforce, HubSpot, and a handful of others have so much training data presence that newer tools rarely surface. But “best CRM for real estate agents” or “best CRM with WhatsApp integration” are subcategory queries where the competitive dynamics are more favorable. Category strategy — choosing where you compete for AI visibility — matters as much as how you compete.
First-Mover Advantage in Model Memory
Brands that were early to establish web presence in a category benefit from a compounding effect. Their mentions appear in earlier training data, which informed earlier model versions, which informed web content that discussed AI recommendations, which fed into later training data. This creates a reinforcement loop that’s difficult for newcomers to break. It doesn’t mean breaking in is impossible — it means you need to be strategic about where you target and realistic about timelines.
The Dark Side: Manipulation, Gaming, and What to Avoid
As AI visibility becomes more valuable, attempts to game the system are accelerating. Understanding these tactics — mostly to avoid them — is part of any serious strategy.
Synthetic Mention Campaigns
Some agencies are running coordinated campaigns to plant brand mentions across forums, guest posts, and low-quality news sites. The theory: more mentions = more training data presence = more AI visibility. In practice, this is the AI equivalent of link farming circa 2010. It might produce short-term results, but it creates fragile, inauthentic signals. When models improve their source quality filtering (and they will), these signals will devalue or become actively harmful.
Content Farm Strategies
Publishing hundreds of thin “best of” articles designed to be picked up by AI crawlers is another common tactic. These articles exist solely to create entity co-occurrence between a brand and target keywords. The problem: models are increasingly good at identifying low-quality, repetitive content. And retrieval systems inherit the quality filters of the search engines they piggyback on. If Bing deprioritizes your content farm articles, ChatGPT Search will never see them.
Recommendation Poisoning
More sophisticated actors attempt to influence AI recommendations through coordinated mention strategies — creating the appearance of organic consensus around a brand through strategically placed content across forums, review sites, and social platforms. This is ethically dubious and practically risky: platforms are getting better at detecting coordinated inauthentic behavior, and the reputational damage of being caught far outweighs any visibility gains.
The Over-Optimization Trap
Even legitimate optimization can backfire when taken too far. Content that reads like it was written for AI extraction rather than human readers loses the authenticity signals that both humans and increasingly sophisticated models look for. If every page on your site follows the exact same “question → direct answer → supporting context” format, it starts looking templated rather than authoritative. The best content for AI visibility is content that would be excellent even if AI didn’t exist.
Measuring What’s Actually Happening
You can’t manage what you can’t measure. But measuring AI visibility requires different approaches than traditional SEO analytics.
Prompt-Based Brand Tracking
The most direct measurement: systematically query AI platforms with relevant prompts and track whether your brand appears. This needs to be done at scale — not one query, but dozens of variations across multiple AI platforms. Tools like Profound, Otterly, and Goodie AI are building automated tracking for this. If you’re doing it manually, maintain a spreadsheet of 20-30 query variations and test monthly across ChatGPT, Gemini, Perplexity, and Claude.
Key principle: test query clusters, not individual queries. If you want to appear for “best PR distribution services,” test “best PR distribution services,” “top press release distribution companies,” “where should I send my press release,” “PR distribution services for startups,” and “affordable press release distribution.” Your visibility pattern across the cluster tells you more than any single query result.
Brand Mention Analysis
Track where your brand is mentioned across the web — and where it isn’t. Tools like Brand24, Mention, or even Google Alerts can identify when and where your brand appears in news, blogs, forums, and social platforms. Compare your mention footprint to competitors. If a competitor has 500 unique domain mentions and you have 50, the visibility gap has a clear cause.
Correlation Over Causation
Be careful about attributing AI visibility changes to specific actions. Because of non-determinism, model updates, and temporal lag, it’s rarely possible to say “we did X and it caused Y.” Instead, track correlations: did a significant increase in media coverage over three months correlate with improved AI visibility for relevant queries? Did a Reddit thread that mentioned your brand positively correlate with Perplexity citing you for that topic? Patterns emerge over time, even if individual data points are noisy.
What Actually Moves the Needle: A Strategy Framework
Based on what we’ve observed across our AI search optimization work, here’s what actually drives measurable improvements in AI brand visibility.
Entity Building as the Core Strategy
Everything flows from entity strength. Your primary goal is to build your brand into a recognizable, well-connected node in the model’s implicit knowledge graph. This means:
Consistent positioning. Pick your category. Own it. Every piece of external content, every interview, every byline, every social media post should reinforce the same core association. If you’re a PR distribution company, every mention should connect your brand to “PR distribution,” “press release,” “media coverage,” and related terms. Scattered positioning creates scattered signals.
Topic ownership. Don’t try to be associated with everything. Choose 3-5 core topics and build deep associations with those. We focus on entity SEO, AI search optimization, and digital PR. Not “marketing” broadly — specific topics where deep association is achievable.
Founder and expert visibility. Personal brands reinforce company brands. When your CEO or subject matter experts publish on LinkedIn, speak at conferences, get quoted in articles, and participate in podcasts, they create additional entity signals that connect back to your brand. Sam Altman doesn’t just represent himself — every mention of him reinforces OpenAI’s entity.
Digital PR as the Primary Lever
Of all the tactics available, sustained digital PR generates the strongest AI visibility signals per unit of effort. A single feature in a relevant industry publication can create more entity signal than months of blog content. A quote in a news article about your industry positions your brand in high-authority training data. A mention in a “best of” article on a respected review site directly drives both training data and retrieval signals.
This isn’t traditional press release distribution (though that has its place). It’s strategic media outreach: pitching expert commentary to journalists, contributing data-driven insights to industry reports, building relationships with reporters who cover your space, and creating genuinely newsworthy moments that earn coverage.
Multi-Platform Distribution
Entity signals strengthen when they appear across diverse platforms. A brand mentioned only on its own website and a few guest posts has a narrow signal profile. A brand discussed on Reddit, cited on Stack Overflow, reviewed on G2, featured in newsletters, quoted in podcasts (which generate transcripts), and mentioned in LinkedIn discussions has a rich, multi-dimensional signal profile that models can triangulate.
Build presence where your audience already discusses topics relevant to your brand. Don’t create fake Reddit accounts or astroturf forums. Genuinely participate. Answer questions. Share insights. The mentions that arise from authentic participation carry more weight than manufactured ones — and they don’t carry the risk of being identified as spam.
Own a Problem Space, Not Just Keywords
Traditional SEO thinks in keywords. AI visibility requires thinking in problem spaces. Instead of targeting “best AI SEO tools,” own the problem of “how do brands become visible in AI answers?” Every piece of content, every external mention, every interview should reinforce your brand’s association with that problem space. When the model encounters a query about that problem — in any phrasing — your brand should have strong enough signals to surface.
Time Horizon: Setting Realistic Expectations
Anyone promising AI visibility results in 30 days is either uninformed or dishonest. Here’s what realistic timelines look like based on what we’ve observed.
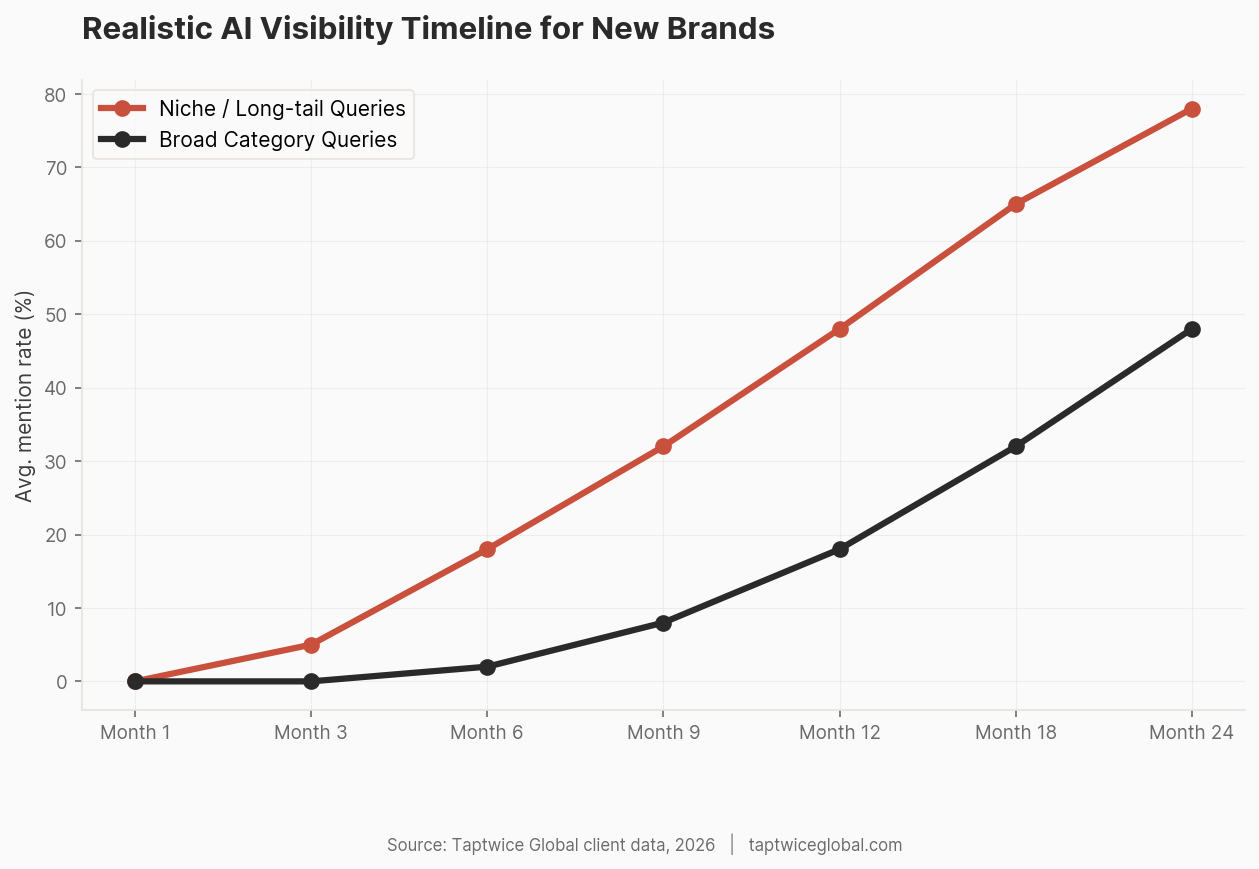
Months 1-3: Foundation
Technical foundations (bot access, index presence, structured content). Initial digital PR outreach. Entity audit: understanding where you stand now, where competitors stand, and where the gaps are. During this period, you should not expect any measurable change in AI visibility. You’re building infrastructure.
Months 3-6: Early Signals
If digital PR is generating coverage and you’re building multi-platform presence, you may start seeing your brand appear in retrieval-based AI answers for niche, specific queries. Broad category queries will still be dominated by established players. This is the phase where most brands get discouraged and stop — which is exactly why the brands that persist build lasting advantages.
Months 6-12: Compounding
Authority signals compound. Media coverage leads to more media coverage. Community mentions lead to more community mentions. As your entity signal strengthens, you start appearing for broader queries. New model training runs may pick up your accumulated signals, moving you from retrieval-only visibility to training-data visibility.
Year 1+: Reinforcement Loops
The most powerful dynamic in AI visibility is the feedback loop: visibility generates more mentions, which generate more visibility. Once you cross a threshold of entity strength, maintaining visibility requires less effort than building it did. But crossing that threshold takes sustained investment. There are no shortcuts that produce durable results.
Where This Is All Heading
AI search is not a stable system. It’s evolving rapidly, and the strategies that work today will need to adapt. Several trends are clear enough to plan around.
From Search to Answer Engines
The fundamental shift is from “ten blue links” to “one generated answer.” Google’s AI Overviews, ChatGPT Search, Perplexity, and Claude are all converging on the same model: users ask questions, AI provides answers, and traditional website visits decline for informational queries. This doesn’t eliminate SEO — it changes what SEO means. Traffic from AI-referred visits is growing, but it flows to fewer sources. The brands that AI systems cite get traffic; the brands they don’t cite get nothing. Middle-of-the-pack visibility is disappearing.
Increasing Personalization
AI models are beginning to incorporate user preferences, conversation history, and behavioral signals into their responses. This means AI answers will become less universal and more personalized. A user who has previously asked about enterprise software will get different brand recommendations than a user who has asked about startup tools. Personalization makes AI visibility harder to measure and harder to predict — but it also creates opportunities for brands that strongly own a specific audience segment.
Stronger Brand Consolidation
As AI answers become the primary way people discover products and services, the concentration effect will intensify. In traditional search, page 2 still gets some traffic. In AI answers, brands that aren’t mentioned get zero. This will accelerate winner-takes-most dynamics in every category and make early investment in AI visibility increasingly valuable.
More Opaque Systems
As AI models grow more complex and multimodal, understanding exactly why one brand appears and another doesn’t will become harder. Model interpretability is an active research area, but for practical purposes, brands will need to focus on building strong signals across all channels rather than trying to reverse-engineer specific model behaviors. The brands that build genuine authority won’t need to understand every model update — they’ll be visible by default.
The Visibility Formula
If we synthesize everything in this piece into a single framework, AI brand visibility is a function of four variables:
Visibility = Entity Strength × Authority Signals × Query Relevance × Model Bias
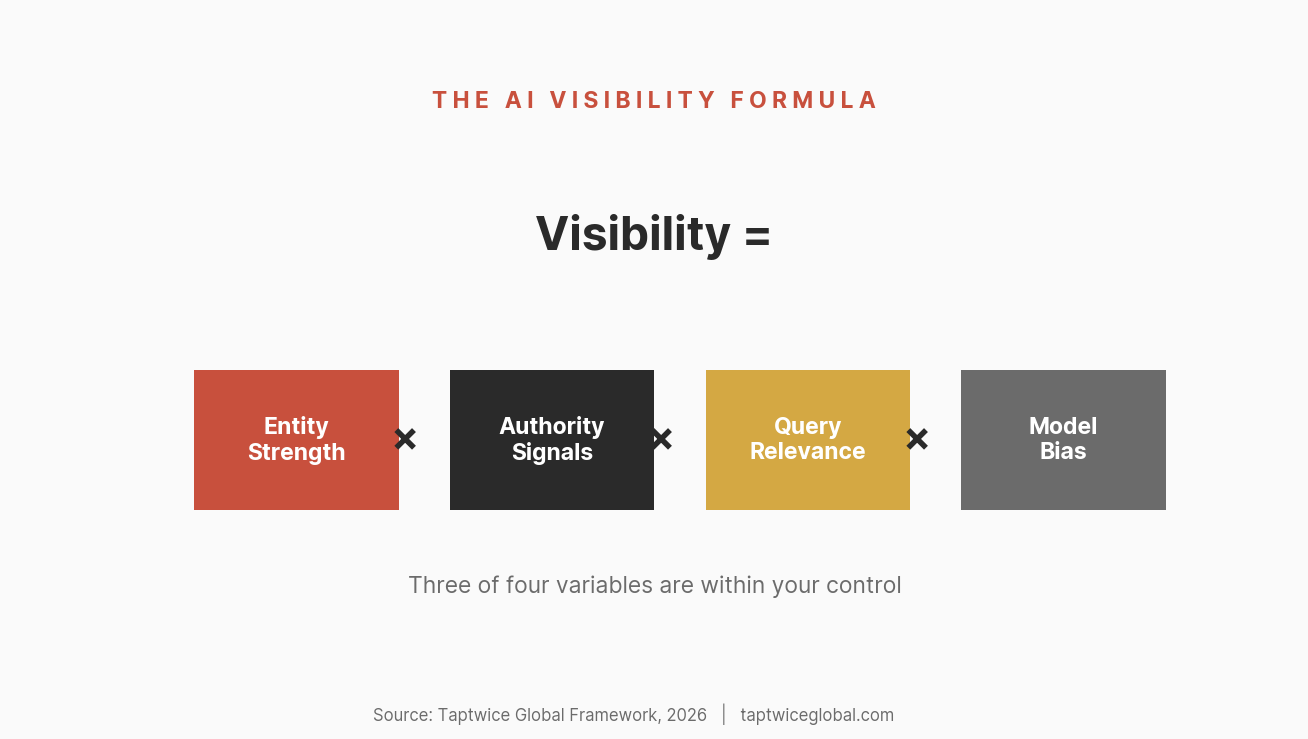
Entity Strength — How well-established your brand is as a recognizable entity: frequency of mentions, context consistency, source diversity, co-occurrence with target topics. Controllable.
Authority Signals — Third-party validation from high-authority sources, media coverage, expert citations, community mentions, platform presence. Largely controllable through sustained effort.
Query Relevance — How closely your brand’s associations match the specific query being asked. Stronger for niche queries where you’ve built deep topical association, weaker for broad category queries dominated by established players. Partially controllable through positioning and content strategy.
Model Bias — Training data composition, source weighting, temporal cutoffs, probabilistic variation, and model architecture decisions. Not controllable.
The strategic implication: focus your energy on the controllable variables. You can’t change how GPT-4 was trained. You can’t control which sources it overweights. But you can build entity strength, generate authority signals, and position your brand for relevant queries. Over time, those controllable factors accumulate enough weight to overcome unfavorable bias.
The brands that understand this — that treat AI visibility as a long-term entity-building exercise rather than a quick optimization hack — are the ones that will dominate the next era of digital discovery. The question isn’t whether AI answers will replace traditional search for discovery. It’s whether your brand will be part of those answers when they do.
Frequently Asked Questions
Why does ChatGPT recommend my competitor but not me?
Your competitor almost certainly has stronger entity signals: more mentions across authoritative third-party sources, more consistent association with your shared category, and more presence in the model’s training data. Check how many unique domains mention your competitor versus you. Look at their media coverage, Reddit mentions, and review site presence. The gap in AI visibility nearly always mirrors a gap in external authority signals. On-site content quality is rarely the differentiator — external footprint is.
Can I pay to appear in ChatGPT responses?
Not directly. As of 2026, OpenAI has publicly discussed plans for advertising within ChatGPT, though direct paid placement in conversational responses is not yet widely available. There is no advertising system, no paid inclusion, and no submission process for brands. What you can pay for indirectly: digital PR services that generate media coverage, content distribution that builds entity signals, and SEO services that improve your presence in Bing (which ChatGPT Search uses for retrieval). But anyone selling “guaranteed ChatGPT placement” is selling something that doesn’t exist. OpenAI has discussed potential ad models, but nothing has been implemented in ChatGPT’s answer generation as of the time of writing.
How long does it take for a new brand to appear in AI answers?
For retrieval-based answers (ChatGPT Search, Perplexity), a new brand can appear within weeks if it has indexed content that’s relevant to the query and ranks in Bing. For training-based answers from the model’s core knowledge, the timeline is much longer — typically months to years, depending on when the next model training run occurs and whether your brand has accumulated enough web mentions to be included. Most new brands see initial AI visibility through retrieval channels within 3-6 months of sustained entity-building activity, with training-based visibility following later.
Does ChatGPT read my website directly?
ChatGPT’s base model does not read your website in real time. It was trained on data collected before its cutoff date and cannot access the live web during standard conversations. However, ChatGPT Search (the browsing-enabled mode) can access your website through Bing’s search index when it determines that web retrieval is needed to answer a query. OpenAI also operates web crawlers (OAI-SearchBot, GPTBot) that may crawl your site for future training data — provided your robots.txt doesn’t block them. So the answer is: not directly during most conversations, but indirectly through search retrieval and potentially through future training data collection.
Why does ChatGPT sometimes mention my brand incorrectly?
This is hallucination — the model generating plausible-sounding but inaccurate information about your brand. It happens most frequently with brands that have weak entity signals: the model knows your brand exists but doesn’t have enough consistent data to generate accurate descriptions. It fills gaps with probabilistic guesses. The solution is strengthening your entity signals with consistent, accurate information across multiple authoritative sources. The more consistent the information the model encounters about your brand, the less likely it is to generate inaccuracies. Having a comprehensive, well-structured About page, Wikipedia presence, and consistent information across directories also helps.
Is there a way to submit my brand to ChatGPT?
No. There is no brand submission system, directory, or registration process for ChatGPT. Unlike Google (which has Search Console) or Bing (which has Webmaster Tools), OpenAI does not offer a way to submit your brand or website for inclusion. Your brand enters the model’s knowledge through two paths: being present in future training data (which requires widespread web mentions) and being retrievable through search engines when ChatGPT Search is active (which requires Bing indexing and traditional SEO). Focus on building your brand’s web presence across authoritative sources, and the AI visibility follows as a downstream effect.